I Spent 8 Iterations Prompt-Engineering an LLM to Read 20-Pixel Icons. A 2005 Algorithm Did It Better.
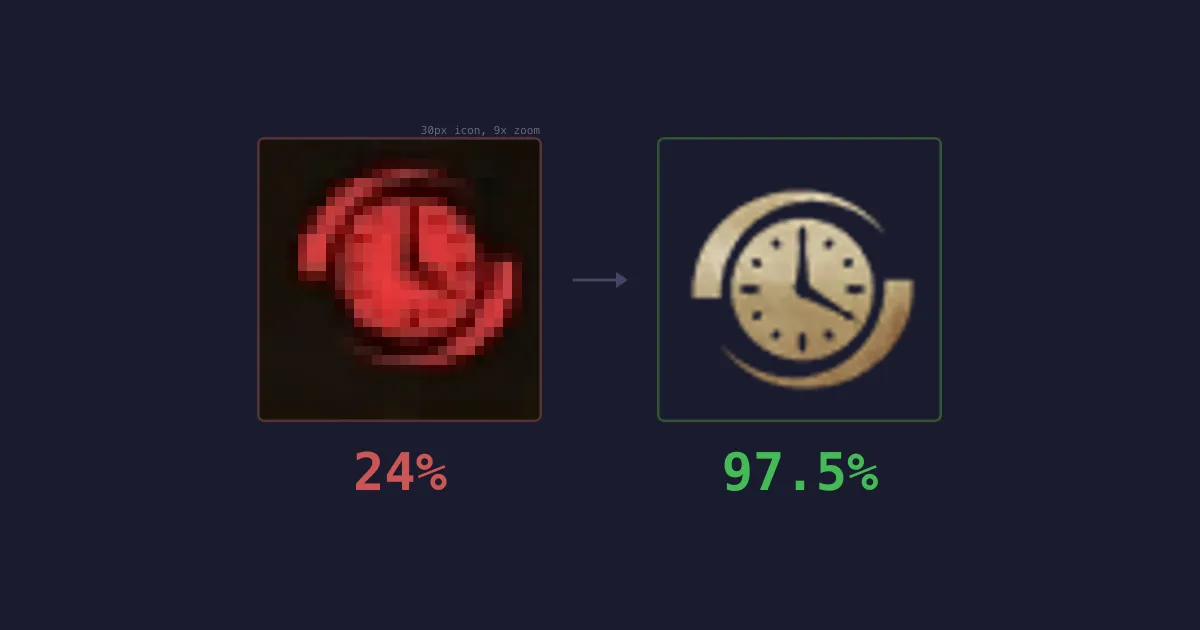
The most expensive AI model on earth scored 17% on a visual classification task. A simple algorithm from 2005, written in 170 lines of code, scored 97.5%. It also ran 100x faster and cost nothing.
This is my story about choosing the right tool - and how the ‘shiny one’ almost cost me weeks.
I built a desktop app that reads a game screenshot, classifies 45 types of tiny (~20 pixel) icons under a 60-second time constraint, and streams tactical advice from an LLM. The complexity driver wasn’t the LLM advice - that part was rather straightforward. Instead, the hardest part was getting structured data out of 20 pixels.
The Shiny Approach
My first prototype sent the screenshot straight to an LLM vision API as is. One call, structured output, no image processing. After 8 iterations of prompt engineering - I tried different models, formats, resolutions, chain-of-thought tricks - the best result was 24% accuracy on icon classification.
I was sure a bigger model would fix it. The most capable model scored 17% - three times worse. It deliberated more, hallucinated features that weren’t there, and second-guessed correct reads. More reasoning power was actively harmful for narrow pattern matching.
The LLM read player names at 99% accuracy. But tiny abstract icons on colored backgrounds were simply unrecognisable for it.
The Boring Approach
I switched to a classical image processing technique from 2005. Nothing exotic - a well-understood way to turn a small image into a compact numerical fingerprint that captures shape. Compare the fingerprint against 45 known references. Closest match wins.
It took 170 lines of code, no fancy ML framework, no GPU, no cloud API, no training data.
97.5% accuracy. 40 milliseconds for 10 icons. $0 per scan. Deterministic.
The Actual Lesson
Here’s the part I didn’t expect. The first version of this same approach only scored 65%. Same algorithm, same references - but the icons were being cropped from the screenshot at slightly wrong positions.
When I fixed the crop pipeline, accuracy jumped from 65% to 97.5% without changing a single line of the classifier. The classifier was fine from day one. It was sitting downstream of sloppy input extraction.
Most accuracy problems aren’t model problems - they are data pipeline problems. I’ve seen this in every data engineering role I’ve held, and it showed up again in a side project where I was free to use anything.
| LLM Vision | Classical Pipeline | |
|---|---|---|
| Accuracy | 24% | 97.5% |
| Cost | ~$0.02/scan | $0 |
| Deterministic | No | Yes |
| Debuggable | No | Yes |
What I’d Tell You Over Coffee
Try the boring approach first. Not because LLMs can’t do vision - naturally they can, impressively - but because general-purpose reasoning is overhead when your problem is specific.
The final version of my system uses both. The local pipeline handles structured extraction - fast, free, deterministic, debuggable. The LLM handles what it’s actually good at: reading text and generating strategic reasoning from structured input.
It’s easy to solve any problem by throwing an LLM at it. Sometimes that’s right. But knowing when it’s not is what keeps your system fast, cheap, and debuggable.
Sometimes the 2005 algorithm is the 2026 solution.
Full technical deep-dive with code and visuals: bogdanov.wtf
Source code: github.com/aleksandr-bogdanov/gw2-cv-pipeline